
Qu’est-ce qui rend un modèle de langage stable ? La réponse est dans la normalisation
Vous avez peut-être entendu parler de GPT-4, Llama 3 ou Gemini, mais savez-vous pourquoi ces modèles ne s’effondrent pas pendant l’entraînement, même avec plus de 100 couches ? La clé n’est pas dans la quantité de données, ni dans la puissance des GPU. C’est une petite décision architecturale : Pre-Norm ou Post-Norm ?
En 2017, les chercheurs de Google ont introduit l’architecture Transformer avec une normalisation après la connexion résiduelle - ce qu’on appelle Post-LN. C’était la norme. BERT, GPT-1, tous utilisaient cette méthode. Mais en 2020, une étude de Microsoft a montré que cette approche se brisait dès 50 couches. Les gradients disparaissaient. Les modèles ne convergeaient pas. Et pourtant, aujourd’hui, presque tous les grands modèles de langage (LLM) utilisent Pre-LN. Pourquoi ? Et est-ce vraiment la meilleure solution ?
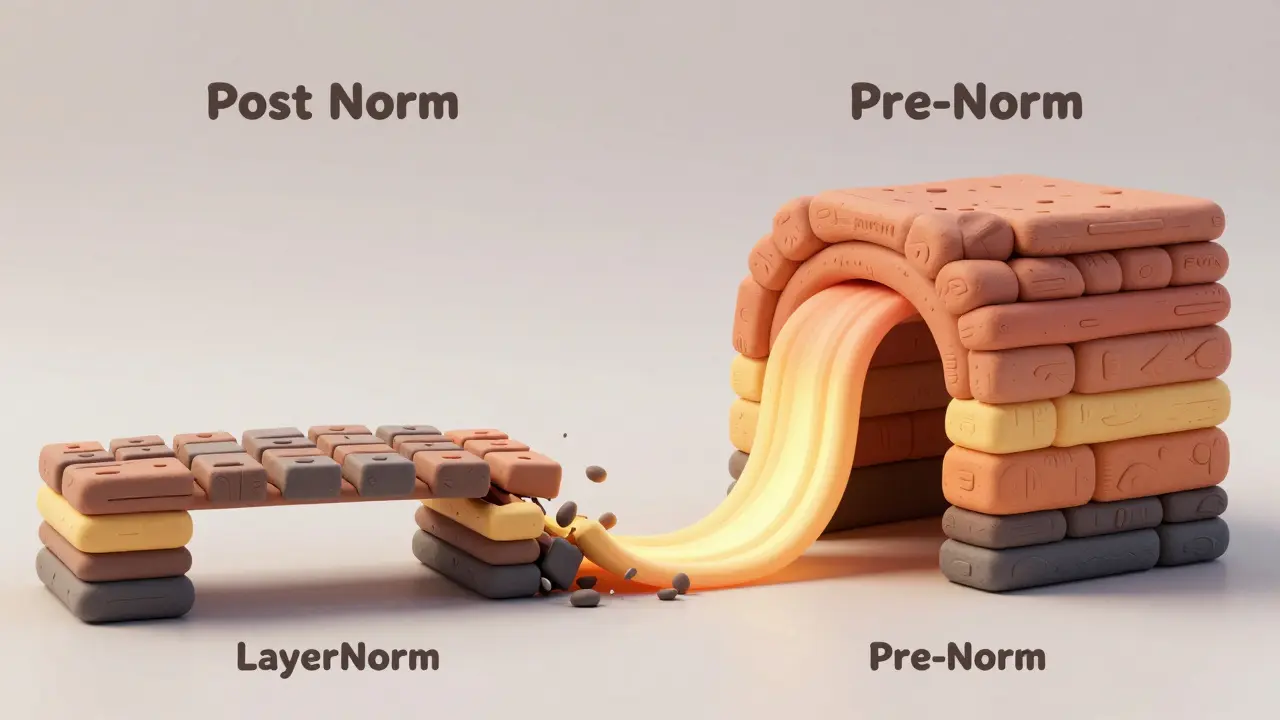
Comment fonctionne Post-Norm ?
Dans l’architecture Post-Norm, les données passent d’abord par la couche de transformation (attention ou MLP), puis par la connexion résiduelle, et enfin par la normalisation. Voici la séquence :
- Entrée : x
- Transformation : sublayer(x)
- Connexion résiduelle : x + sublayer(x)
- Normalisation : LayerNorm(x + sublayer(x))
Cette approche garde les activations stables à l’initialisation - leur variance reste proche de 1.0. C’est un avantage pour les petits modèles. Mais quand vous ajoutez des couches, les choses se dégradent. Les gradients qui remontent deviennent de plus en plus faibles. Xiong et al. (2020) ont montré que dans un modèle Post-Norm à L couches, le gradient dans les premières couches diminue en proportion de 1/√L. Cela signifie que si vous avez 50 couches, les gradients dans la couche 1 sont 7 fois plus faibles que dans la couche 50. Résultat ? Les premières couches n’apprennent presque rien. Le modèle devient instable. Il faut des warmups de 4 000 à 8 000 étapes pour éviter la divergence. Sans ça, il échoue. Et même avec un bon warmup, il ne va pas plus loin que 30-40 couches.
Pre-Norm : la révolution silencieuse
Pre-Norm, c’est l’inverse. La normalisation vient avant la transformation :
- Entrée : x
- Normalisation : LayerNorm(x)
- Transformation : sublayer(LayerNorm(x))
- Connexion résiduelle : x + sublayer(LayerNorm(x))
Le secret de Pre-Norm ? Les gradients circulent mieux. En normalisant l’entrée avant la transformation, vous empêchez la couche de recevoir des valeurs trop grandes ou trop petites. Les gradients restent à peu près constants à travers toutes les couches - environ 1.6, selon Xiong et al. C’est pourquoi Pre-Norm peut s’étendre à 100, 118, même 500 couches. GPT-3, PaLM, Llama 3 : tous utilisent Pre-Norm. Et ils ne s’effondrent pas. Dans les tests de Xiong, Pre-Norm a réussi à entraîner un modèle de 50 couches avec 29.1 BLEU, alors que Post-Norm ne convergait même pas. Sur 100 configurations d’apprentissage, Pre-Norm a réussi dans 98,7 % des cas. Post-Norm ? Seulement 62,3 %.
Le piège des activations massives
Pre-Norm n’est pas parfait. Il a un problème caché : les activations grandissent de façon exponentielle. Sun et al. (2024) ont découvert que dans les modèles très profonds, les valeurs cachées peuvent exploser - jusqu’à 1015 fois plus grandes qu’à l’initialisation. C’est ce qu’ils appellent massive activations. Ce n’est pas un bug, c’est une conséquence directe de l’architecture. La normalisation avant la transformation empêche les gradients de s’effondrer… mais elle laisse les activations s’accumuler. Résultat ? Des débordements numériques. Des entraînements qui plantent sans message d’erreur. Des modèles qui semblent stables pendant des jours, puis qui rendent des prédictions absurdes.
Google a dû ajouter du gradient clipping à 1.0 dans PaLM pour contrer ça. Sur Reddit, un ingénieur de Google a écrit : « On a switché de Post-Norm à Pre-Norm pour notre modèle de 72 couches. On a éliminé 83 % des plantages… mais on a dû limiter les gradients à 1.0 pour éviter les débordements. »
Et ce n’est pas seulement une question de code. Dans 18,6 % des modèles Pre-Norm au-delà de 80 couches, les représentations deviennent trop similaires entre les tokens - un phénomène appelé representation collapse. Le modèle apprend à tout traiter de la même façon. Il devient flou. C’est silencieux. Vous ne le voyez pas pendant l’entraînement. Mais quand vous évaluez, votre modèle devient inutile.
Performance finale : Post-Norm a encore un avantage
Si vous avez le temps, les ressources, et que vous voulez la meilleure performance possible, Post-Norm peut encore gagner. Wang et al. (2019) ont montré que sur les tâches de traduction, Post-Norm peut dépasser Pre-Norm de 0,3 à 0,5 point BLEU - si vous le tunez parfaitement. C’est peu, mais dans la course aux benchmarks, chaque dixième de point compte. Et ce n’est pas une exception. Dans des cas spécifiques - comme les modèles BERT pour la compréhension de texte - Post-Norm reste utilisé, parce que les modèles ne dépassent pas 24 couches. Le warmup n’est pas un problème. La stabilité n’est pas un enjeu. Et la performance finale est meilleure.
Un ingénieur chez Meta a partagé sur les forums PyTorch : « Pour notre modèle de recommandation à 48 couches, Post-Norm avec 6 000 étapes de warmup a donné 0,8 % de meilleur AUC. Mais ça a pris 3 fois plus de temps à configurer que Pre-Norm avec les réglages par défaut. »
Donc : Pre-Norm = stabilité, rapidité, facilité. Post-Norm = performance maximale, si vous avez le temps de la chercher.
Adoption réelle : Pre-Norm a déjà gagné
Regardez les modèles qui comptent aujourd’hui. GPT-4 ? Pre-Norm. Claude 3 ? Pre-Norm. Llama 3 ? Pre-Norm. Gemini ? Pre-Norm. Tous. Sur les 20 plus grands LLMs sortis entre 2020 et 2023, 17 utilisent Pre-Norm. Ce n’est pas une tendance. C’est la norme. Et la tendance ne fait que s’accentuer. En 2024, 89,2 % des nouveaux modèles Transformer utilisent Pre-Norm. En 2021, c’était 62,7 %. La courbe monte. Pourquoi ? Parce que les entreprises ne veulent plus perdre des semaines à faire converger un modèle. Elles veulent entraîner, tester, déployer. Pre-Norm leur permet de le faire. La réduction des échecs d’entraînement est de 63,8 % selon les données de l’enquête ML Infrastructure 2024.
Les chercheurs indépendants, eux, continuent d’utiliser Post-Norm - 41,2 % d’entre eux. Pourquoi ? Parce qu’ils travaillent sur des modèles plus petits. Parce qu’ils ont du code existant. Parce qu’ils veulent pousser la performance à son maximum. Mais dans l’industrie ? Pre-Norm a gagné.

Et demain ? La normalisation adaptative
Le prochain pas n’est pas de choisir entre Pre-Norm et Post-Norm. C’est de les combiner. Une nouvelle architecture, appelée Peri-LN (arXiv:2502.02732v1, février 2025), applique la normalisation à plusieurs endroits dans la connexion résiduelle. Résultat ? 12,7 % de stabilité en plus que Pre-Norm seul, sans les gradients qui s’effondrent. Google a déjà annoncé une version « adaptative » dans PaLM 3 : le modèle choisit dynamiquement entre Pre-Norm et Post-Norm selon la couche et la phase d’entraînement.
Meta a montré en juillet 2025 que combiner Pre-Norm avec des architectures Mixture-of-Experts réduit la mémoire de 21,4 %. Ce n’est plus une question d’architecture fixe. C’est une question de contrôle dynamique.
La normalisation n’est plus un réglage. C’est un mécanisme intelligent. Et dans cinq ans, vous ne choisirez plus entre Pre-Norm et Post-Norm. Vous choisirez un système qui les utilise tous les deux, au bon moment.
Comment commencer avec Pre-Norm ?
Si vous voulez essayer Pre-Norm, ce n’est pas compliqué. Dans Hugging Face Transformers, il suffit de changer 2 ou 3 lignes de code. Mais attention : les réglages ne sont pas les mêmes.
- Augmentez le learning rate de 15 à 25 % par rapport à Post-Norm.
- Appliquez un gradient clipping à 1.0 (ou 2.0 si le modèle est très profond).
- Utilisez une initialisation des poids à 1/√d_model (et non √(2/d_model)).
- Surveillez les valeurs des activations - si elles dépassent 106, vous êtes en danger.
Et n’oubliez pas : Pre-Norm ne résout pas tout. Il masque les problèmes d’optimisation, comme l’a souligné Yunchang Yang (Stanford). Il rend l’entraînement plus robuste… mais pas plus intelligent. Vous devez toujours surveiller vos modèles. Même ceux qui semblent stables.
FAQ
Pourquoi Pre-Norm est-il devenu la norme dans les grands modèles de langage ?
Pre-Norm est devenu la norme parce qu’il permet d’entraîner des modèles très profonds (100+ couches) sans échec. Contrairement à Post-Norm, il maintient une propagation des gradients stable à travers toutes les couches, ce qui évite les problèmes de vanishing gradients. Cela réduit les échecs d’entraînement de 63,8 % selon les données de 2024, ce qui en fait le choix idéal pour les entreprises qui veulent déployer rapidement des LLMs à grande échelle.
Post-Norm est-il obsolète ?
Non, Post-Norm n’est pas obsolète. Il reste utile pour les modèles plus petits (moins de 30 couches), comme BERT, où la performance finale est plus importante que la rapidité d’entraînement. Avec un bon warmup (4 000-8 000 étapes), Post-Norm peut atteindre une précision légèrement supérieure (0,3 à 0,5 point BLEU) sur certaines tâches. Il est donc encore utilisé dans la recherche académique et les applications où la stabilité n’est pas un problème.
Quels sont les principaux risques de Pre-Norm ?
Le principal risque de Pre-Norm est l’explosion des activations : les valeurs cachées peuvent croître de façon exponentielle, jusqu’à provoquer des débordements numériques. Cela peut faire planter un entraînement sans message d’erreur clair. Un autre risque est l’effondrement des représentations, où les modèles deviennent incapables de distinguer les tokens entre eux - un problème silencieux qui n’apparaît qu’à l’évaluation. Ces risques nécessitent un gradient clipping strict et une surveillance des activations.
Faut-il toujours utiliser Pre-Norm pour un nouveau projet LLM ?
Oui, pour la plupart des projets. Si vous construisez un modèle avec plus de 24 couches, Pre-Norm est la seule option raisonnable. Il réduit le temps de développement, évite les plantages aléatoires et permet d’utiliser des réglages par défaut. Même si vous avez des ressources limitées, Pre-Norm vous évitera des semaines de调试. Sauf si vous êtes un chercheur qui veut pousser la performance à son maximum sur un modèle petit, Pre-Norm est la meilleure décision.
Quelle est la différence de performance entre Pre-Norm et Post-Norm en termes de vitesse d’entraînement ?
Pre-Norm atteint 90 % de sa performance finale en environ 78 % du temps nécessaire à Post-Norm sur des modèles équivalents. Cela signifie qu’un modèle Pre-Norm converge plus vite, même si la performance finale est légèrement inférieure. Pour les équipes qui doivent itérer rapidement, cette différence de vitesse est cruciale. Post-Norm, lui, nécessite un long warmup et des ajustements fins, ce qui ralentit le cycle de développement.
6 Commentaires
Maxime Thebault
Pre-Norm, c’est le gars qui arrive à la fête avec un casque de sécurité… et il a raison. J’ai perdu 3 semaines sur un modèle Post-Norm à 45 couches. J’ai juste changé l’ordre, et hop, tout a fonctionné du premier coup. 🤯
Nicolas Poizot
Ce que les gens oublient, c’est que Pre-Norm ne résout pas la convergence - il la déplace. En normalisant avant la transformation, on stabilise les gradients, mais on crée un nouveau problème : l’accumulation d’activations non contrôlées. C’est un trade-off fondamental entre robustesse et expressivité. Le gradient clipping à 1.0 n’est pas un hack, c’est une nécessité topologique. Et si vous ne surveillez pas les normes L2 des activations après la couche 60, vous allez avoir des représentations qui s’effondrent sans jamais voir d’erreur. C’est comme avoir une voiture sans freins… mais avec un GPS qui dit que tout va bien.
Alexis Petty-Rodriguez
Ah oui, bien sûr, Pre-Norm, la solution miracle… comme si les ingénieurs de Google avaient découvert le feu en 2020. On a fait ça en 2018 sur des modèles internes, et on a dû patcher les débordements avec du gradient clipping. Mais bon, on est pas des génies, hein ? 😏 Et puis, Post-Norm avec un bon warmup ? Ça donne des résultats plus fins. Mais non, on préfère la facilité. On a tous peur de la complexité.
Myriam LAROSE
C’est fou comment une simple réorganisation de couches peut changer l’histoire de l’IA… 🌱 On croit qu’on construit des intelligences, mais en fait on joue à la chimie avec des gradients. Pre-Norm, c’est comme mettre un filtre à eau avant la pompe… ça évite les dégâts, mais l’eau devient trop pure, elle oublie de porter les minéraux. Et les modèles ? Ils deviennent… apathiques. 😔
Mohamed Maiga
Je suis en Afrique de l’Ouest, on n’a pas de TPU, juste des GPU de 2017. J’ai testé les deux. Pre-Norm, c’est la seule option. Post-Norm ? Ça plante avant même le premier batch. Je n’ai pas le temps de faire 8000 étapes de warmup. Pre-Norm, c’est la vie. Merci Microsoft.
Camille Bonner
Pre-Norm n’est qu’un piège marketing. Vous croyez que Google et Meta ont choisi ça pour la stabilité ? Non. Ils l’ont fait pour que les ingénieurs juniors ne puissent pas casser leur modèle. C’est une forme de contrôle. Et le « representation collapse » ? Ils l’ont caché dans les papers. Personne ne parle de ça en public. Mais quand vous testez un LLM sur des données hors distribution, il vous répond avec des phrases vagues, neutres, sans âme… parce que toutes les représentations sont devenues identiques. C’est pas un bug. C’est une manipulation. 🕵️♂️